스파크 스프리밍은 실시간으로 유입되는 데이터 처리를 위한 스파크 기반의 프레임워크이다. 크게 DStream 방식과 Structured Streaming 방식을 지원한다.
DStream 방식은 예전 스파크 버전에서 사용하던 방법이며, 자바, 파이썬 객체에 대한 저수준 연산만 지원하기 때문에 고수준의 최적화 기법을 활용하는데 한계를 가진다.
그러나 Structured Streaming 방식은 Dataframe, Dataset과 통합할 수 있는 스트리밍 시스템으로 2.0 이후 추가되었고 2.2 이후 안정화되어 사용 사례가 빠르게 늘고 있다.
Structured Streaming 방식
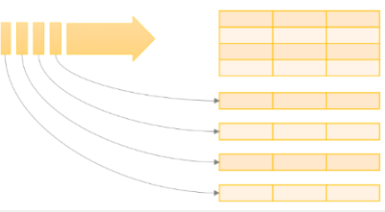
실시간으로 유입되는 데이터는 위와 같이 Dataframe 형식으로 관리된다.
그렇다보니 쉽게 데이터 조작이나 직관적으로 이해 하기가 쉽다.
또한 데이터를 Dataframe 형식으로 관리하기 때문에 미리 스키마에 대한 선언이 필요하다.
WordCount 예제
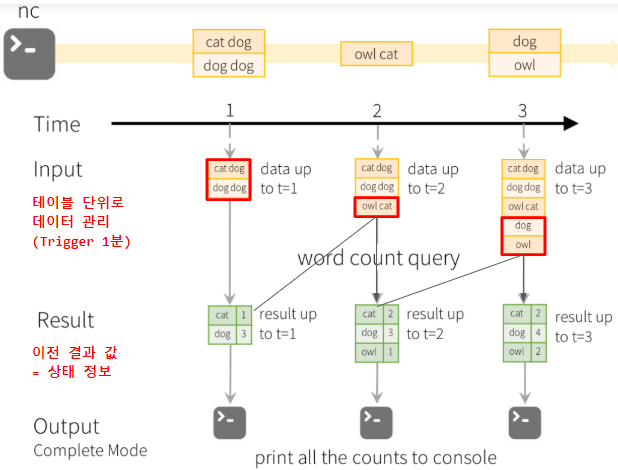
위 그림과 같이 WordCount 과정을 살펴보자.
- 트리거는 1분으로 1분 단위로 WordCount가 실행된다.
- structured streaming은 신규 유입되는 데이터에 대해서만 쿼리가 수행된다.
- 출력 결과는 이전 결과(상태 정보)와 신규 유입되는 데이터의 WordCount에 대한 결과가 출력된다.
출력 모드 비교
Structured Streaming은 출력 방식이 3가지가 존재한다.
각 차이는 아래 그림을 통해 확인한다.

출력 모드 예제
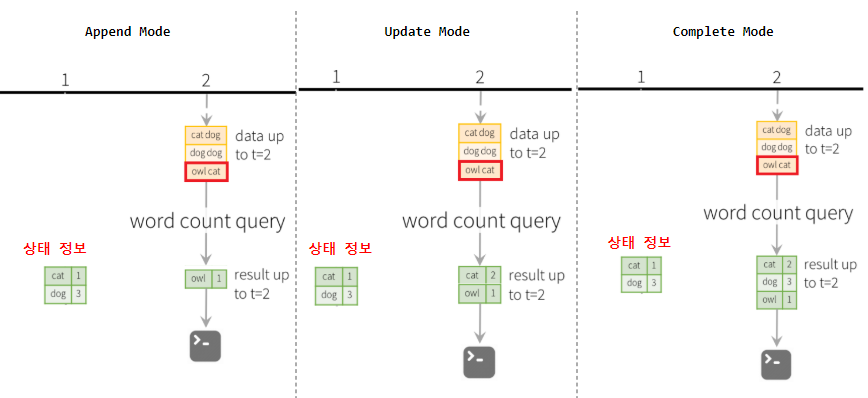
위 그림은 WordCount 예제의 각 출력 모드를 각 볼 수 있다.
Append Mode는 예제 설명을 위해 넣은 그림이며, 기본적으로 Aggregation에서 사용하기 위해서는 Window, WaterMark 같은 설정이 필요하다.
Window
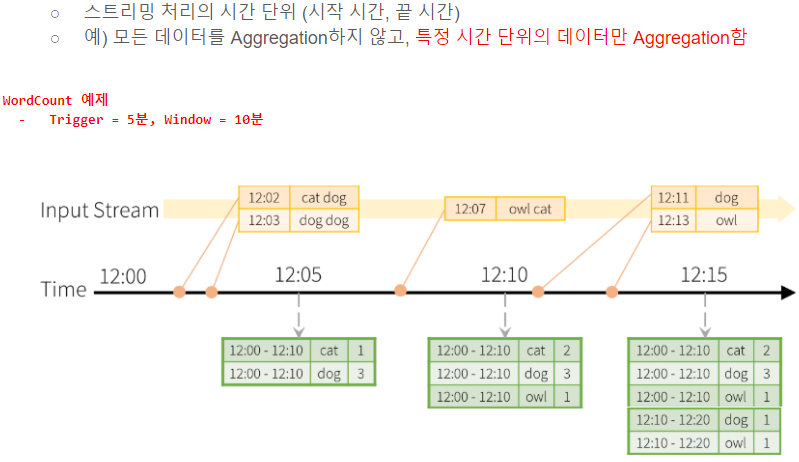
Spark Streaming 어플리케이션 목적은 신규 유입되는 데이터의 경향이나 분석을 위해 사용하기 때문에 Window를 통해 집계 단위를 묶어 처리하는 것이 좋다.
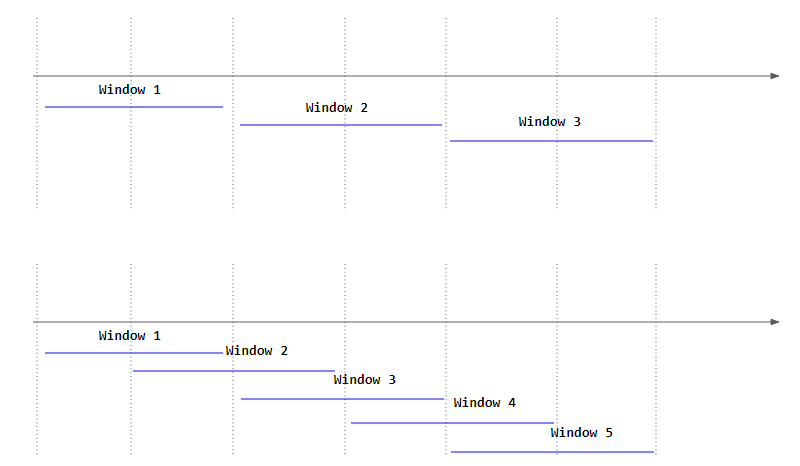
Sliding Window

Sliding Window를 통해 여러 Window에 결과를 중첩할 수 있다.
이를 위해 Window 보다 낮은 값으로 설정해야 한다.
Window, Sliding Window의 차이 비교
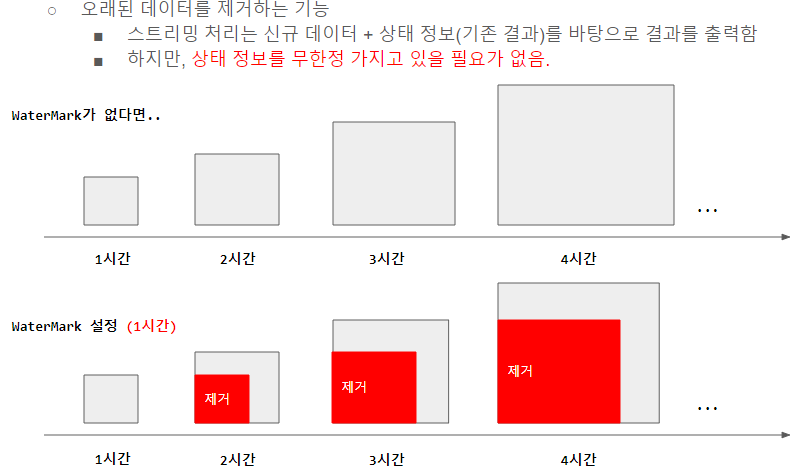
WaterMark
참고
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#stream-stream-joins
Comments